
Understanding the Relational Database Concept
Now that you have covered tables and brought some data into the database, you can turn your focus to one of the more useful features of Access: relationships. Access relationships are the mechanism by which separate tables are related to each other. The idea behind relationships is the Relational Database Concept. Before you begin to directly create relationships between Access tables, take a closer look at the concept behind relational database systems.
Why Is This Concept Important?
This concept is important because it is the theoretical framework from which most database programs are designed. If you want to understand just how databases work, you need to understand this concept. You are learning Access, among other reasons, because the data storage and data manipulation capacity of Excel is insufficient for your analysis needs. The concept that dictates just how data is stored and structured is the Relational Database Concept. Even though you may have no intention of becoming a database administrator, having some understanding about how the data that you would like to analyze has been stored and structured will increase your performance and productivity. It will also promote better communication between you and the I.T. department and the database administrator, since now you will be able to understand at least some of the vocabulary of the database language.
Excel and the Flat-File Format
Before you cover the proper techniques for storing data in Access, examine the common data storage scenario that led to the problems that the concept attempts to address. Even if they are not aware of the term flat-file format, most Excel users are very adept at working with data that has been stored in it. In fact, most people in general are familiar with the concept because it is used in so many things that you encounter every day. The flat-file, of course, organizes data into rows and columns.
There are data analysis scenarios that are not terribly complex in which a flat-file representation of the data to be analyzed is adequate. However, most data-analysis scenarios require analyzing data that is much more multi-dimensional. One of the main reasons that the flat-file can prove inadequate is that it is two-dimensional. Real-world business data rarely falls into a convenient, two-dimensional format. Of course, it can be forced into that format by the Excel guru who wants all analysis to fit into the spreadsheet. Take a look at a typical example of a flat-file. Figure below shows a typical flat-file list of invoices.
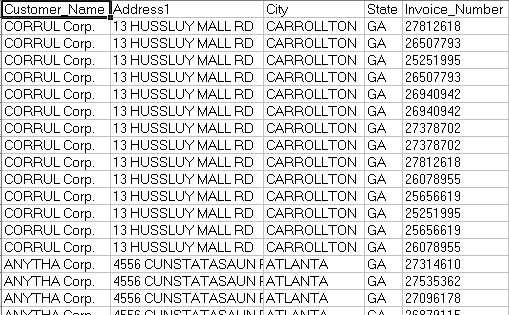
In order to get the customer information for each invoice, there are several fields for customer-specific information such as customer name, address, city, and so on. Since most firms sell to customers more than once, for each invoice the same customer information has to be repeated. Duplicate information is one of the main drawbacks of the flat-file format.
What is wrong with duplicate data? Initially, the duplicate data may not appear to be a potential source of future problems, but upon further examination, you discover the shortcomings. First is the size of the file. Duplicate data wastes space, both on the computer hard drive, where the file is stored, and in the computer's memory, where the data resides when it is being used. Although the enormous amount of memory that is standard with today's machines goes a long way to handling these demands, you are wasting valuable computer space and resources. The duplicate information is not valuable. In fact, it leads to problems.
One of the main problems that can arise from too much duplicate data occurs when that data needs to be updated. In the previous example, there are several invoices for CORRUL Corp. You can also see that you have to repeat the information about the customer for each instance of an invoice. Imagine a scenario where the customer information might change. For example, the customer acquires new office space, and you want to reflect this change of location in your data. Looking at the preceding list, you see that you will have to update the change in several different places. You need to ensure that every invoice will correctly map back to its relevant customer information.
Although there are excellent functions that find and replace data in Excel, there is still a danger that you might not make all of the updates correctly. Whenever you are changing duplicate information, there is always the risk of introducing unintentional errors. This could significantly affect your data analysis. For example, imagine that customer CORRUL Corp. moved not just to a different address, but a different city.
If the City data is not properly updated everywhere, when you attempt a by city filter/analysis, you will not get accurate results. Some of the invoice records could reflect the incorrect state locations of the customer. The attributes of data can and often do change. If these changes are not accurately recorded, your data analysis is providing an incorrect picture of the actual situation.
In this tutorial:
- MS-Access Basics
- Access Tables
- Table Basics
- Exploring Data Types
- Creating a Table with Design View
- Access Field Properties and Primary Key
- Getting Data into Access
- Understanding the Relational Database Concept
- Splitting Data into Separate Tables
- Relationship Types
- Query Basics
- Creating Your First Select Query